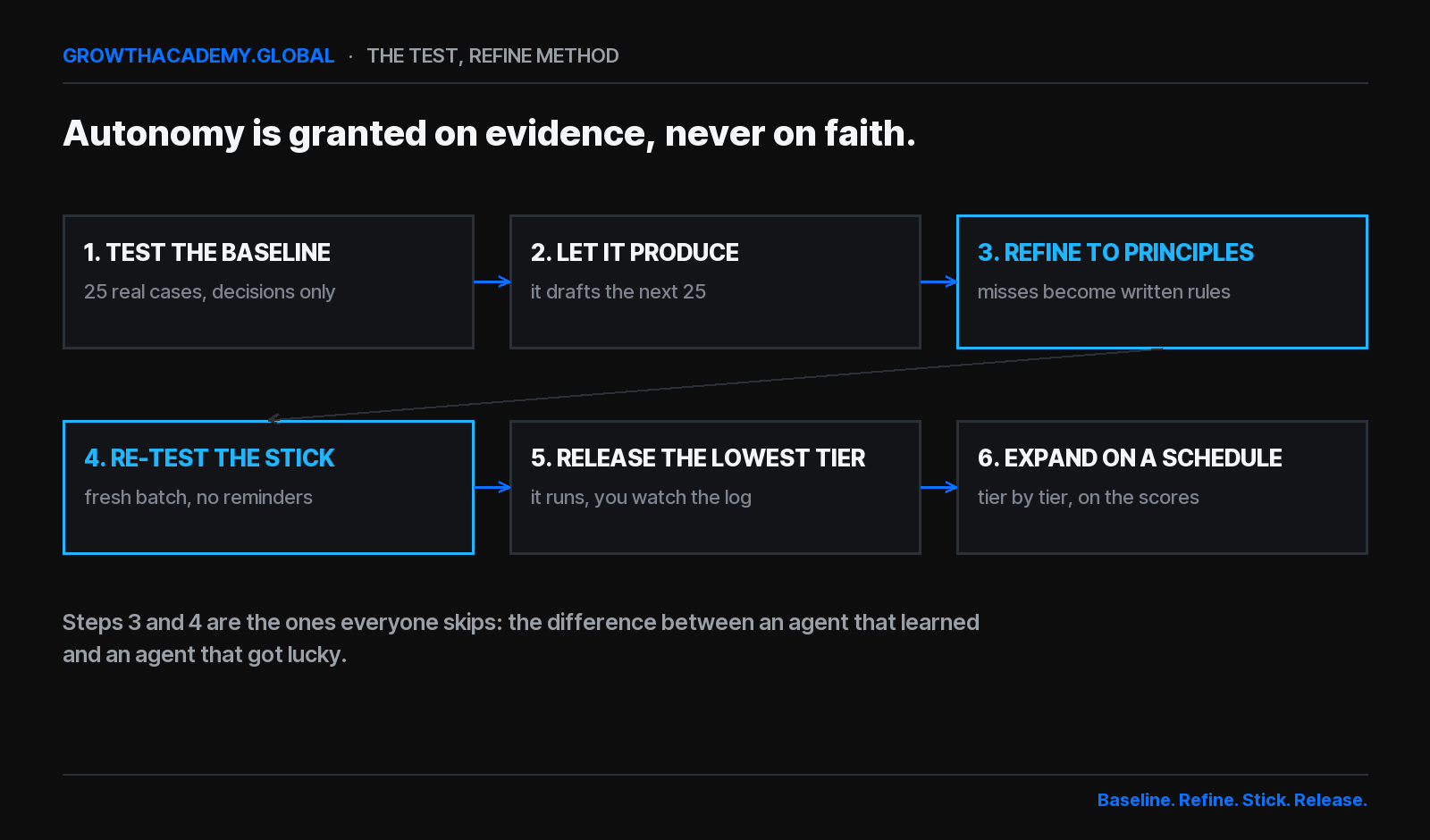
Short answer: A prompt is advice. An agent is an employee. The Test, Refine method is how one becomes the other, in six steps: test the baseline on about 25 real historical cases (decisions only), let it produce drafts on the next 25, refine the misses into written principles, re-test a fresh batch to prove the principles stick, release the lowest-stakes tier while you watch the log, and expand tier by tier on a schedule as the scores hold. Autonomy is granted on evidence, never on faith. Run on a real inbox, this took one client from roughly ten hours of email a week to about two.
A prompt is advice. An agent is an employee.
Every owner I work with has a prompt graveyard: clever instructions that produced one good answer and then went back to being a note in a doc. A prompt waits for you. You run it, you read it, you act on it, and all the work still belongs to you. An agent is different the way an employee is different: it has a job, a schedule, a standard, and a record. The gap between the two is not better software. It is a method, and the method is mostly testing.
People ask me how a prompt turns into an agent, expecting a tool recommendation. The honest answer is a ladder. First the prompt runs manually and you act on it. Then it runs on a schedule but only drafts, nothing leaves without you. Then, after it posts scores, it earns the right to act on the lowest-stakes tier on its own, logged. Then its lane expands, tier by tier. Same instruction. What changed is how much it is allowed to do without you, and every inch of that was earned.
Ten hours of email a week, down to two
Here is the method run on a real desk. The client: a consultant with enterprise clients, a self-described control freak about her own voice, and an inbox eating roughly ten hours of her week. Email was the agent she asked for, which matters: start where the pain is, not where the demo is impressive.
- Test the baseline. Twenty-five real emails from her actual history. The agent's only job: decide respond, delete, or escalate, and grade each email's priority, level 1 to 3. No drafting, no sending, just judgment. Score: 25 out of 25. Now we knew the decision layer worked before a single word got written.
- Let it produce. Another 25, this time drafting the replies it believed were needed, in her voice, learned from her own sent mail. She would have sent all but four as-is.
- Refine the misses into principles. This is the step that separates the method from tinkering. We did not just fix the four drafts. We asked what rule each miss revealed and wrote it down for the agent to carry forward. One of hers was as small as pronouns: where she says "we" versus "I." That became a standing instruction, not a correction she would have to make twice.
- Re-test that the principles stick. A fresh batch, specifically checking that the refinements held with no reminders. This is the step everyone skips, and it is the difference between an agent that learned and an agent that got lucky.
- Release the lowest tier. The level-1 emails, the routine ones, started running without her. And I will tell you what that moment actually felt like, because pretending it is easy helps nobody. She typed the instruction, stopped at the enter key, and said, "I can't." Her stomach turned. She pressed it anyway, and spent the next few days watching the log instead of her inbox.
- Expand on a schedule, not a feeling. The scores held, so that Saturday the agent took level 2 as well, with everything client-facing still waiting for her reply. Tier by tier, on evidence.
The result, a few weeks in: the agent triages everything, handles the routine tier on its own, and drafts the rest for one-reply approval. Her ten hours of email became about two, and the two that remain are decisions, not typing. A control freak granted autonomy in days, not because she relaxed, but because the agent posted scores at every step.
The three rules that make release safe
These hold from day one, on every agent, no exceptions: every action is logged, so you can audit exactly what it did and why. Anything client-facing or financial waits for a human reply until that tier has earned its release. And you can switch the whole thing off in one step. Those are the seatbelts. With them on, releasing a tier is a decision you can defend. Without them, it is a gamble you got away with.
Run the baseline on your own inbox today
You do not need a build, a budget, or a free week. You need 25 old emails and this prompt. Paste it into your agent (Codex or Claude Code, connected to your email, with permissions set so it can actually work):
Read my last 25 received emails. For each one, decide: respond, delete or archive, or escalate to me. Grade each email's priority from 1 to 3, where 1 is routine and 3 is something only I should handle. Do not reply to anything, do not delete anything, do not change anything.
Show me your 25 decisions in a table with one line of reasoning each, so I can grade you. Then tell me which decisions you were least confident about and why.
Grade it like a hiring manager, not a fan. Count the misses. If it goes 20-plus out of 25, run round two and let it draft. If it misses more, look at what it could not see, because the cause is usually access, not intelligence, and connect the missing context before judging the agent.
Where this goes wrong
Three failure patterns account for almost every abandoned agent I see. (A fourth, taking the agent's first "I can't" at face value, gets its own article.) Owners fix drafts one at a time instead of extracting the principle, so the agent makes the same miss forever and trust never compounds. Owners skip the stick-test and release on a good first impression, then one bad week later they switch it all off. And owners release everything at once instead of a tier, get burned on something that mattered, and tell everyone the technology is not ready. The technology was ready. The method was missing. And if your instinct after four misses is to quit, read the honest answer on agents and your admin team, four misses on round two is not failure, it is the curriculum.
Common questions
What is the Test, Refine method?
A six-step process for turning a prompt into an agent you can trust: test the baseline on about 25 real historical cases with decisions only, let it produce drafts on the next 25, refine the misses into written principles, re-test a fresh batch to prove the principles stick, release the lowest-stakes tier while watching the log, and expand tier by tier on a schedule as the scores hold. Autonomy is granted on evidence, never on faith.
How does a prompt turn into an agent?
Through graduated autonomy, not different software. A prompt is something you run manually and act on yourself. It becomes an agent in stages: first it runs on a schedule but only drafts, then it earns the right to act on the lowest-stakes tier after scored tests, then its lane expands as the scores hold. The tool is the same. What changes is how much it is allowed to do without you, and that is earned.
How many tests before I can trust an AI agent?
Plan on about 25 cases per round and at least three rounds: a decisions-only baseline, a drafting round, and a stick-test round after you refine the misses into principles. Trust is granted per tier, so the lowest-stakes work releases first and everything above it waits for scores.
What if the agent gets things wrong?
It will, and that is the method working. The misses in round two are the raw material: turn each one into a written principle the agent carries forward, then re-test to confirm the principle stuck. An agent that went 21 of 25 and then held its refinements on a fresh batch is more trustworthy than one that happened to go 25 for 25 once.
Is it safe to let an AI agent send emails?
With guardrails, yes. Three rules hold from day one: every action is logged, anything client-facing or financial waits for a human reply until that tier has earned release, and you can switch the whole thing off in one step. The agent earns the routine sends through scored tests; it does not start with them.
How much time does this actually save?
The client in this story went from roughly ten hours of email a week to about two. The agent triages everything, handles the routine tier on its own, and drafts the rest for approval, so her remaining email time is decisions, not typing.
Stop collecting prompts. Pick the job that eats your week, run the baseline today, and make the agent earn its lane the same way you would make a hire earn theirs: with scores.
Keep going: the method inside a full conversion is the SOPs-into-agents playbook, the bigger argument is it's not SOP, it's HASOP, and the revenue version is the 12 prompts that find money in your business.